CodeBotler + RoboEval
Deploying and Evaluating LLMs to Program Service Mobile Robots
Accepted at IEEE Robotics and Automation Letters (RA-L)
- Zichao Hu1,
- Francesca Lucchetti2,
- Claire Schlesinger2,
- Yash Saxena1,
- Anders Freeman3,
- Sadanand Modak1,
- Arjun Guha2,
- Joydeep Biswas1
 Code
Code
 Paper
Paper
CodeBotler is an open-source tool to generate robot programs from natural language using LLMs, and to enable robot-agnostic deployment of such programs. RoboEval is a benchmark to evaluate LLM-generated robot programs for service mobile robots.
Abstract
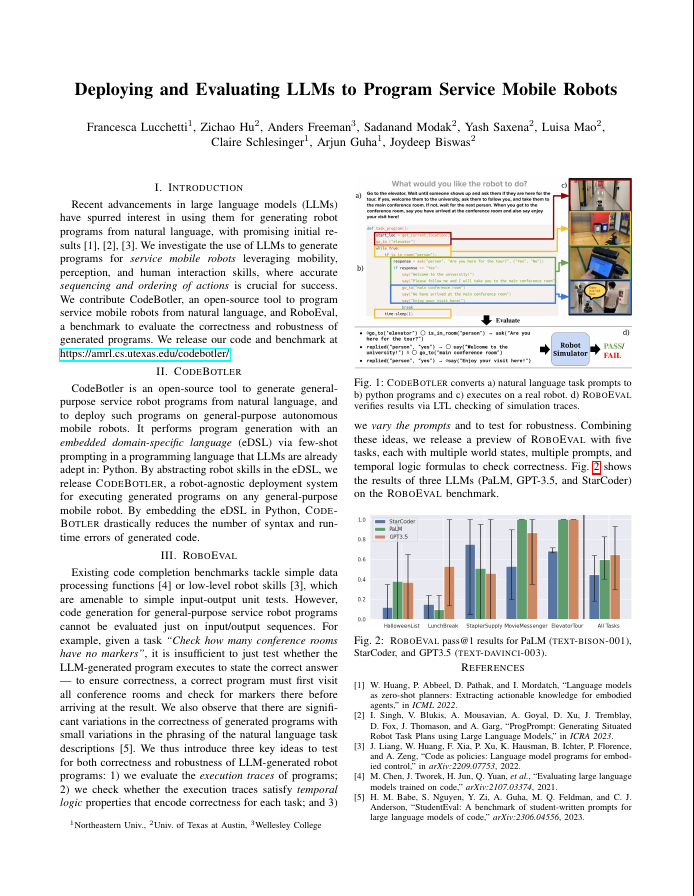
Recent advancements in large language models (LLMs) have spurred interest in using them for generating robot programs from natural language, with promising initial results. We investigate the use of LLMs to generate programs for service mobile robots leveraging mobility, perception, and human interaction skills, and where accurate sequencing and ordering of actions is crucial for success. We contribute CodeBotler , an open-source robot-agnostic tool to program service mobile robots from natural language, and RoboEval, a benchmark for evaluating LLMs’ capabilities of generating programs to complete service robot tasks. CodeBotler performs program generation via few-shot prompting of LLMs with an embedded domain-specific language (eDSL) in Python, and leverages skill abstractions to deploy generated programs on any general-purpose mobile robot. RoboEval evaluates the correctness of generated programs by checking execution traces starting with multiple initial states, and checking whether the traces satisfy temporal logic properties that encode correctness for each task. RoboEval also includes multiple prompts per task to test for the robustness of program generation. We evaluate several popular state-of-the-art LLMs with the RoboEval benchmark, and perform a thorough analysis of the modes of failures, resulting in a taxonomy that highlights common pitfalls of LLMs at generating robot programs.
CodeBotler Demo
CodeBotler Robot Skills and RoboEval Temporal Checks
CodeBotler leverages an embedded domain-specific language (eDSL) in Python to abstract 8 commonly available service robot skills shown in (a). Given a user task description, CodeBotler constructs a service robot program. RoboEval is a benchmark that contains a suite of 16 different user tasks, each with 5 prompt paraphrases, totalling 80 different prompts. To evaluate a service robot program generated from the benchmark tasks, RoboEval contains a symbolic simulator and a temporal trace evaluator. The symbolic simulator executes the program and outputs a trace of robot skills. Then the temporal trace evaluator uses the RoboEval Temporal Logic (RTL) specifications to evaluate the correctness of the program. The definition of the RTL is shown below in (b).

RoboEval Benchmark Tasks and Evaluations
We investigate the capabilities and limitations of five popular state-of-the-art LLMs for generating service mobile robot LMPs:
- GPT4 (
gpt-4-0613): A proprietary LLM from OpenAI capable of general language tasks, including code generation. - GPT3.5 (
text-davinci-003): A proprietary LLM from OpenAI capable of general language tasks, including code generation. - PaLM 2 (
text-bison-001): A proprietary LLM from Google with multiple capabilities, including code generation. - CodeLlama (
codellama/CodeLlama-34b-Python-hf): An open-access version of Llama 2 from Meta specialized on code generations. - StarCoder (
bigcode/starcoder): An open-source 15.5B parameter LLM trained on 80+ programming languages from The Stack.
These LLMs are evaluated on the RoboEval benchmark which consists of 16 user tasks, each with 5 prompt paraphrases, totaling 80 different prompts. For each prompt, we generate 50 program completions and calculate the pass@1 score. Below, we present the details of each user task and the pass@1 score of each LLM over every prompt.
| Task Details | |||
|---|---|---|---|
| Prompts |
|
||
| Properties | Number of World States | ||
Causes of Program Failures
Citation
@ARTICLE{10416558,
author={Hu, Zichao and Lucchetti, Francesca and Schlesinger, Claire and Saxena, Yash and Freeman, Anders and Modak, Sadanand and Guha, Arjun and Biswas, Joydeep},
journal={IEEE Robotics and Automation Letters},
title={Deploying and Evaluating LLMs to Program Service Mobile Robots},
year={2024},
volume={9},
number={3},
pages={2853-2860},
keywords={Robots;Task analysis;Benchmark testing;Natural languages;Python;Mobile robots;Service robots;Software tools for benchmarking and reproducibility;software tools for robot programming;social HRI;human-centered robotics;service robotics},
doi={10.1109/LRA.2024.3360020}
}