Overview
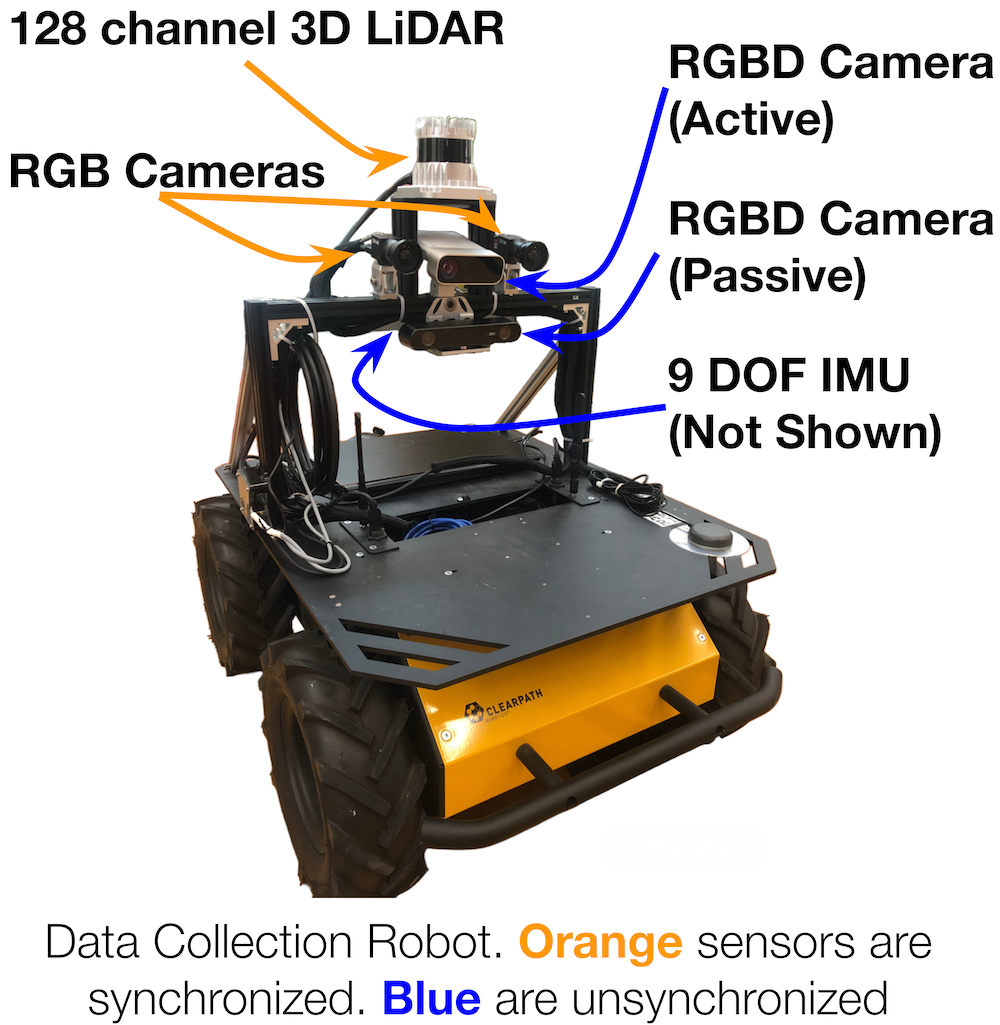

Location and orientation of each robot sensor. Precise calibrations for each sensor are available in the data report
- 8.5 hours of multimodal sensor data
- 3D point clouds from a 128-channel 3D LiDAR
- Stereo RGB video from two 1.25MP RGB cameras at 10 fps
- RGB-D videos from additional 0.5MP sensors at 7 fps
- 9-Degree of Freedom (DOF) Inertial data from an IMU sensor at 40 Hz
Routes

Map of all geographic locations used for dataset collection on UT Austin campus.
Robot operators teleoperated the robot along five distinct geographic locations. We refer to different trials as sequences. Under this definition, we have 22 sequences in our dataset. We define each sequence by the order of waypoints and describe the waypoints more in the data report. We mark these waypoints, shown on the map, (e.g. G2), prior to data collection so that waypoint locations are identical between sequences.
Data Format
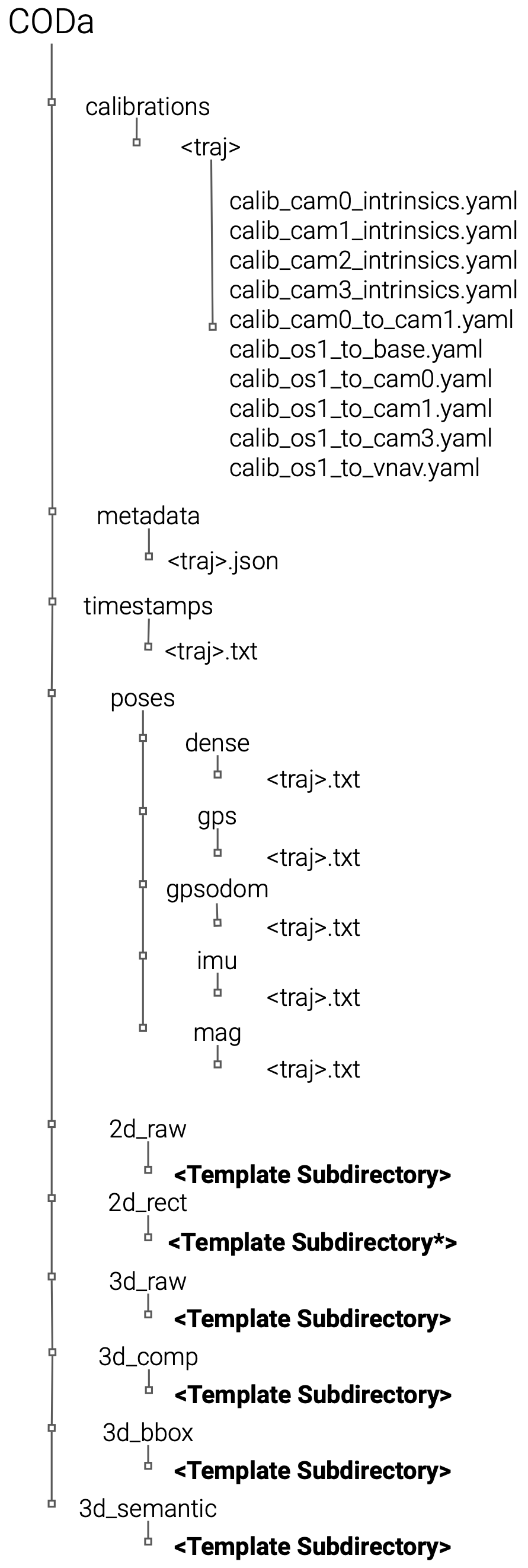

CODa is organized in the following levels: the data modality (2D/3D), sensor type, and sequence number. We recommend users first inspect the metadata under the metadata directory to understand which files should be used for their task. The metadata files contain the file paths to the ground truth annotations relative to the root location where CODa is downloaded on your file system. They also provide summaries of all the unique objects for each sequence.
We abbreviate the sensors as follows:
3D LiDAR - os1
Left Stereo RGB Camera - cam0
Right Stereo RGB Camera - cam1
Azure Kinect RGBD Camera - cam2
ZED 2I RGBD Camera - cam3
VectorNav GPS/IMU- vnav
Annotation Format
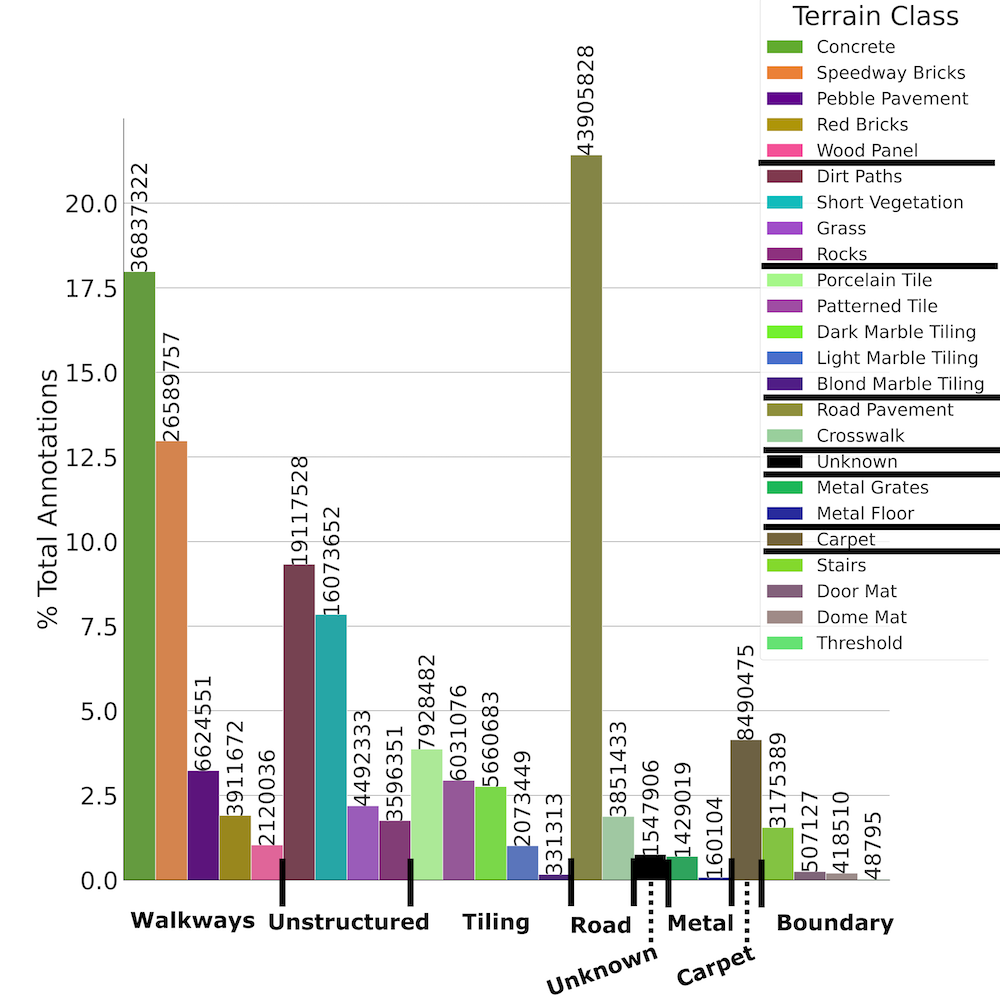
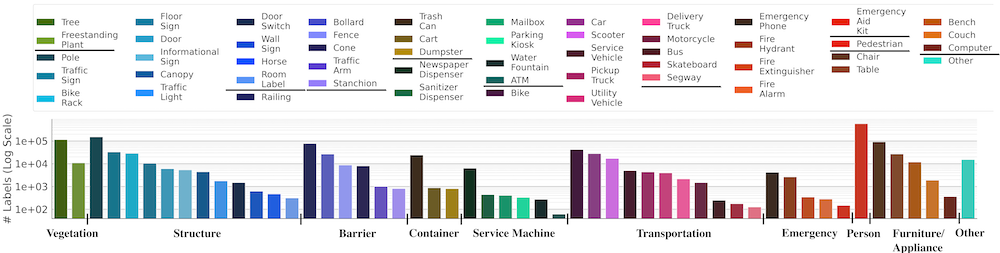
We provide a summary of the terrain ontology (left) and object ontology (bottom) available in CODa. For a detailed description of the annotation format and examples of each class, please refer to the data report.
CODa Development Kit
The CODa Development Kit provides tools for converting rosbag files into individual files organized using the CODa file structure. For instance, the script will synchronize any number of topics provided, assign these synchronized topics to a unified frame number, and save each topic (LiDAR, camera, audio, inertial) to its own data file. Furthermore, the script will republish specified topics in the bag file over ROS to work in conjunction with packages with ROS interfaces. Beyond this, the package also provides 3D and 2D visualization tools for the data. For more information, please visit our CODa DevKit Repository
CODa Models
The CODa Models provides tools for deploying pretrained 3D object detectors and reproducing results in our paper. We provide a script for using pretrained models on live ROS point clouds and an offline Open3D based visualization tool. For more information, please visit our CODa Models Repository